


Dans le secteur de l’AB testing, il existe deux méthodes majeures pour interpréter les résultats d’un test : fréquentiste ou bayésienne.
Ces termes font référence à deux méthodes de statistiques inférentielles. Des débats houleux visent à déterminer la « meilleure » solution mais chez AB Tasty, nous savons quelle méthode a fini par gagner nos faveurs.
Que vous soyez à la recherche d’une solution d’AB testing, que vous découvriez le domaine ou que vous cherchiez simplement à mieux interpréter les résultats d’une expérience, il est essentiel de comprendre la logique de chaque méthode. Cela vous aidera à prendre de meilleures décisions commerciales et/ou à choisir la meilleure plateforme d’expérimentation.
Dans cet article, nous allons évoquer :
[toc]
Définition des statistiques inférentielles
Les méthodes fréquentistes et bayésiennes appartiennent à la branche des statistiques inférentielles. Contrairement aux statistiques descriptives (qui comme leur nom l’indique, décrivent exclusivement des événements passés), les statistiques inférentielles visent à induire ou à anticiper des événements futurs. De la version A ou la version B, laquelle aura un meilleur impact sur un KPI X ?
À savoir : Pour entrer un peu plus dans les détails, techniquement, les statistiques inférentielles ne consistent pas à anticiper au sens temporel du terme, mais à extrapoler ce qu’il se passera en appliquant les résultats à un plus grand nombre de participants. Que se passe-t-il si nous proposons la version B gagnante à l’ensemble de l’audience de mon site web ? La notion d’événements « futurs » est bien présente dans le sens où nous devrons effectivement implémenter la version B demain, mais nous n’utilisons pas les statistiques pour « prédire l’avenir » au sens strict.
Prenons un exemple. Imaginons que vous soyez fan de sports olympiques et que vous vouliez en apprendre davantage sur une équipe de natation masculine. Plus précisément, combien mesurent les membres de l’équipe ? Grâce aux statistiques descriptives, vous pourriez déterminer quelques données intéressantes à propos de l’échantillon (autrement dit, l’équipe) :
- La taille moyenne de l’échantillon
- L’étalement de l’échantillon (variance)
- Le nombre de personnes en dessous ou au-dessus de la moyenne
- Etc.
Cela peut répondre à vos besoins immédiats mais le périmètre est relativement limité. Les statistiques inférentielles vous permettent d’induire des conclusions à des échantillons trop importants pour être étudiés par une approche descriptive. Si vous vouliez connaître la taille moyenne de tous les hommes sur la planète, il serait impossible d’aller collecter toutes ces données. En revanche, vous pouvez utiliser les statistiques inférentielles pour induire cette moyenne à partir de différents échantillons, plus limités.
On peut induire ce type d’information par l’analyse statistique de deux manières : à l’aide des méthodes fréquentiste et bayésienne.
Définition des statistiques fréquentistes
L’approche fréquentiste vous est peut-être plus familière car elle est plus fréquemment utilisée par les logiciels d’A/B testing (sans vouloir faire de mauvais jeu de mot…). Elle est également souvent enseignée dans les cours de statistiques en études suppérieures.
Cette approche vise à prendre une décision à propos d’une expérience unique.
Avec l’approche fréquentiste, vous partez de l’hypothèse selon laquelle il n’y a pas de différence entre la version A et la version B du test. Au terme de votre expérience, vous obtiendrez ce que l’on appelle la P-valeur (valeur de probabilité).
La « pValue » (valeur-p) désigne la probabilité d’obtenir des résultats au moins aussi extrêmes que les résultats observés, en partant du principe qu’il n’y a pas de (réelle) différence entre les expériences.
En pratique, la valeur-p est interprétée pour signifier la probabilité qu’il n’y a aucune différence entre vos deux versions. (C’est pour cela qu’elle est souvent “inversée” en utilisant la formule basique : p = 1-valeur-p, afin d’exprimer la probabilité qu’il existe une différence).
Plus la valeur-p est faible, plus élevées sont les chances qu’il existe effectivement une différence, et donc que votre hypothèse est fausse.
Avantages de l’approche fréquentiste :
- Les modèles fréquentistes sont disponibles dans n’importe quelle bibliothèque de statistiques pour tous les langages de programmation.
- Le calcul des tests fréquentistes est ultra-rapide.
Inconvénients de l’approche fréquentiste :
- La valeur-p est uniquement estimée à l’issue d’un test et non pendant. Regarder régulièrement les données (data peeking) avant la fin d’un test génère des résultats trompeurs car il s’agit alors de plusieurs expériences (une nouvelle à chaque fois que vous examinez les données) quand le test est conçu pour une seule expérience.
- Vous ne pouvez pas connaître le réel intervalle de gain d’une variation gagnante.
Définition des statistiques bayésiennes
L’approche bayésienne explore les choses sous un angle un peu différent.
Son origine remonte à un charmant mathématicien britannique du nom de Thomas Bayes et à son éponyme théorème de Bayes.
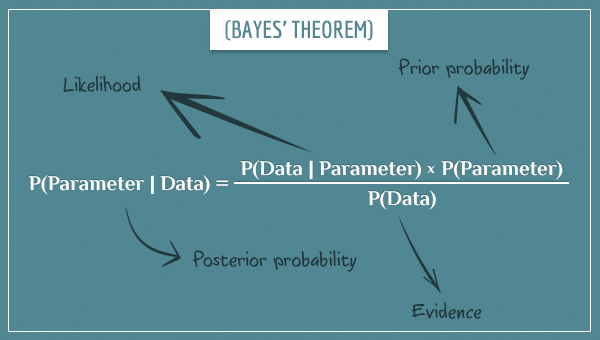
L’approche bayésienne permet d’inclure des informations antérieures (« a priori ») à votre analyse actuelle. Cette méthode fait intervenir trois concepts qui se recoupent :
- Un a priori, à savoir une information obtenue d’une expérience précédente. Au début de l’expérience, nous utilisons un a priori « non-informatif » (comprendre « vide »).
- Des preuves, c’est à dire les données de l’expérience actuelle.
- Un posteriori, soit l’information actualisée obtenue à partir de l’a priori et des preuves. C’est ce que l’on obtient par l’analyse bayésienne.
Par nature, ce test peut être utilisé pour une expérience en cours. Lors du data peeking, les données observées peuvent servir d’a priori, les données à venir seront les preuves, et ainsi de suite. Cela signifie que le « data peeking » s’intègre naturellement à la conception du test. Ainsi, à chaque data peeking, le posteriori calculé par l’analyse bayésienne est valide.
L’approche bayésienne permet aux professionnels du CRO d’estimer le gain d’une variation gagnante : un élément fondamental de l’A/B testing dans un contexte business. Nous reviendrons plus tard sur ce point.
Avantages de l’approche bayésienne :
- Elle permet d’observer les données pendant un test. Ainsi, vous pouvez stopper le traffic si une variation échoue ou bien passer plus rapidement à une variation gagnante évidente.
- Elle vous permet de connaître le réel intervalle de gain d’un test gagnant.
- Par nature, elle élimine souvent l’implémentation de faux positifs.
Inconvénients de l’approche bayésienne :
- Elle nécessite une boucle d’échantillonnage qui utilise une charge CPU non-négligeable. Ce n’est pas un problème pour l’utilisateur mais cela peut potentiellement poser problème à plus grande échelle.
Approche bayésienne vs. fréquentiste
Alors, quelle est la « meilleure » méthode ?
Commençons par préciser que ces méthodes statistiques sont toutes les deux parfaitement valables. Mais chez AB Tasty, nous avons une nette préférence pour l’approche bayésienne. Pourquoi ?
La mesure du gain
L’une des raisons principales est que les statistiques bayésiennes vous permettent d’évaluer l’ampleur du gain réel d’une variation gagnante, plutôt que de savoir uniquement qu’il s’agit de la gagnante.
Dans un cadre business, il s’agit d’une distinction cruciale. Lorsque vous effectuez votre test A/B, ce que vous êtes réellement en train de décider, c’est si vous devez passer de la variation A à la variation B. Il ne s’agit pas de choisir A ou B en partant de zéro. Il faut donc prendre en compte :
- Le coût de mise en oeuvre du passage à la variation B (temps, ressources, budget)
- Les coûts additionnels liés à la variation B (coûts de la solution, licences…)
Prenons un exemple : imaginons que vous commercialisez un logiciel B2B et que vous exécutez un test A/B sur votre page tarifs. La variation B comprenait un chatbot, absent dans la variation A. La variation B a surperformé par rapport à la A mais pour l’implémenter, il faudra deux semaines à un développeur pour intégrer le chatbot à votre workflow de lead nurturing. En outre, il faudra dégager X euros de budget marketing pour payer la licence mensuelle du chatbot.
Il faut être sûr de votre calcul et qu’il est plus rentable d’opter pour la version B en comparant ces coûts avec le gain estimé par le test. C’est exactement ce que permet l’approche bayésienne.
Prenons un exemple en observant l’interface de reporting AB Tasty.
Dans ce test fictif, nous mesurerons trois variations contre une version d’origine en prenant les « Clics CTA » comme KPI.
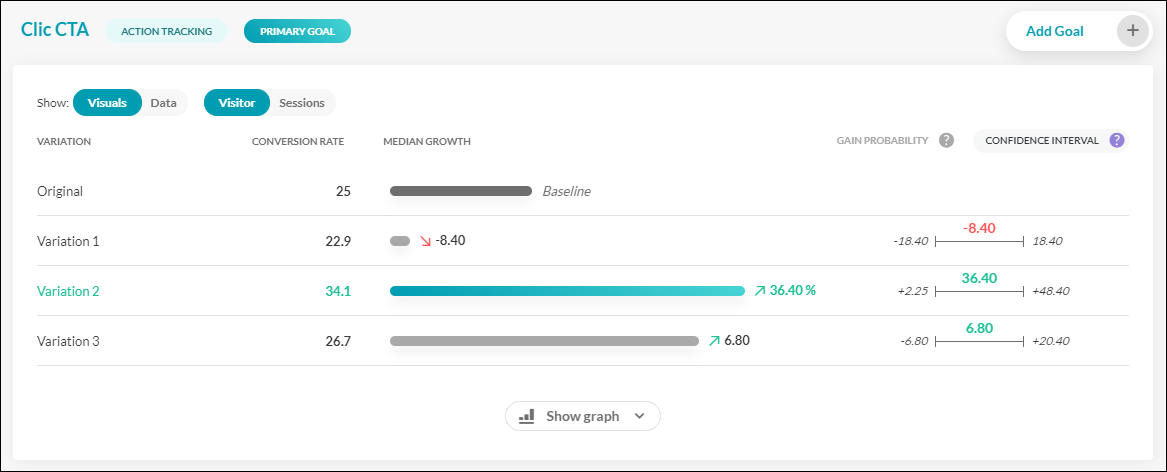
On peut constater que la grande gagnante semble être la variation 2, avec un taux de conversion de 34,5 %, comparé à 25 % pour la version d’origine. Mais en regardant à droite, nous pouvons aussi voir l’intervalle de confiance de ce gain. Autrement dit, nous tenons compte du meilleur et du pire scénario.
Le gain médian de la variation 2 s’élève à 36,4 %. Ici le gain le plus faible possible est + 2,25 % et le plus élevé, 48,40 %. Il s’agit des bornes de gain les plus faibles et les plus élevés que vous pouvez obtenir dans 95 % des cas. Si l’on décompose les choses davantage :
- Il y a 50 % de chances que le pourcentage de gain percentage soit supérieur à 36,4 % (la médiane)
- Il y a 50 % de chances qu’il soit inférieur à 36,4 %.
- Dans 95 % des cas, le gain sera dans la fourchette entre + 2,25 % et + 48,40 %.
- Il reste 2,5 % de chances que le gain soit inférieur à 2,25 % (le fameux cas du faux positif) et 2,5% de chances qu’il soit supérieur à 48,40 %.
Ce niveau de granularité peut vous aider à choisir de déployer ou non la variation gagnante d’un test sur votre site internet. Les extrémités les plus faibles et les plus élevées de vos marqueurs de gain sont positives ? Fantastique ! L’intervalle de confiance est étroit, donc vous êtes convaincu d’un gain élevé ? Implémenter la version gagnante est alors probablement la bonne décision. Votre intervalle est large mais les coûts d’implémentation sont bas ? Là encore, il n’y a pas de mal à se lancer. En revanche, si votre intervalle est large et que les coûts d’implémentation sont conséquents, il vaut sans doute mieux attendre d’avoir davantage de données pour réduire cet intervalle. Chez AB Tasty, nous recommandons généralement :
- D’attendre avant d’avoir enregistré au moins 5 000 visiteurs uniques par variation ;
- De faire durer le test au moins 14 jours (deux cycles commerciaux) ;
- D’attendre d’avoir atteint 300 conversions sur votre objectif principal.
Data peeking
Les statistiques bayésiennes offrent un autre avantage : grâce à elles, vous pouvez jeter un coup d’œil aux résultats de vos données pendant un test (sans en abuser tout de même !).
Imaginons que vous travaillez pour une grande plateforme d’e-commerce et que vous effectuez un test A/B concernant une nouvelle offre promotionnelle. Si vous remarquez que la variation B affiche des résultats pitoyables (vous faisant perdre beaucoup d’argent au passage), vous pouvez stopper le test immédiatement !
A l’inverse, si votre test surperforme, vous pouvez transférer tout le trafic de votre site web vers la version gagnante plus rapidement que si vous employiez la méthode fréquentiste.
C’est la logique précise qui gouverne notre fonctionnalité d’allocation dynamique de trafic… qui n’aurait jamais été possible sans M. Thomas Bayes !
Allocation dynamique de trafic
Si nous nous arrêtons rapidement sur le sujet de l’allocation dynamique de trafic, nous verrons qu’elle est particulièrement utile dans un cadre commercial ou dans des contextes instables ou limités en termes de temps.
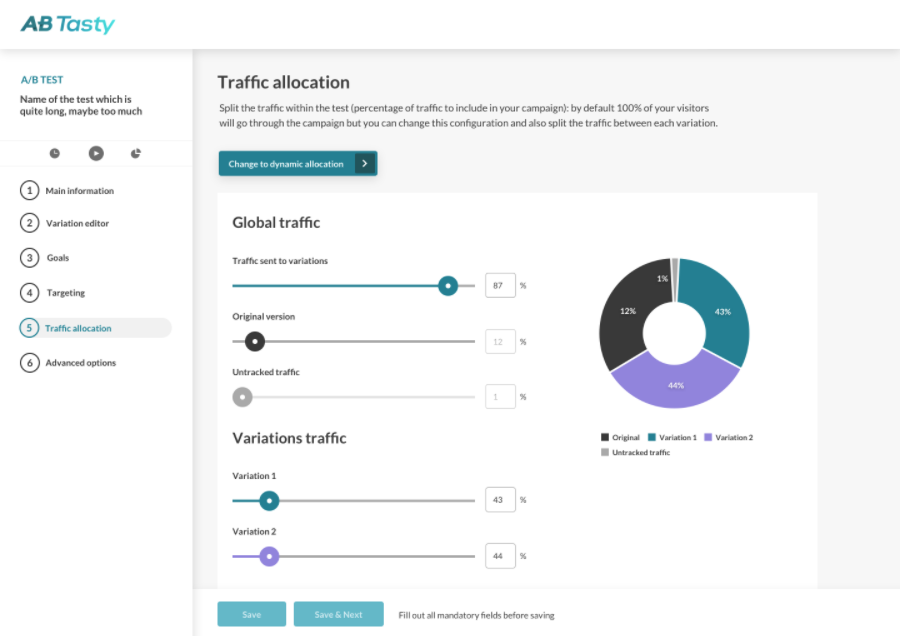
L’option d’allocation dynamique de trafic dans l’interface AB Tasty
L’allocation dynamique de trafic (automatisée) permet essentiellement de trouver l’équilibre entre l’exploration et l’exploitation des données. Les données du test font l’objet d’une « exploration » suffisamment approfondie pour être certain de la conclusion et elles sont « exploitées » suffisamment tôt pour de ne pas perdre inutilement des conversions (ou tout autre KPI). Il faut souligner que ce processus ne se fait pas manuellement : ce n’est pas une personne en chair et en os qui interprète ces résultats et prend la décision. Au lieu de cela, un algorithme va faire ce choix pour vous automatiquement.
Dans la pratique, les clients AB Tasty cochent la case correspondante et choisissent leur KPI principal. L’algorithme de la plateforme déterminera alors s’il faut rediriger la majorité de votre trafic vers une variation gagnante et du moment opportun pour le faire.
Ce type d’approche est particulièrement utile dans les situations suivantes :
- Pour optimiser les micro-conversions dans un délai court
- Lorsque la durée du test est courte (par exemple, lors d’une promotion pendant les fêtes)
- Lorsque votre page cible génère peu de trafic
- Lorsque vous testez plus de six variations
S’il faut bien réfléchir au moment opportun pour utiliser cette option, il est particulièrement utile de l’avoir sous le coude.
Les faux positifs
Tout comme les méthodes fréquentistes, les statistiques bayésiennes comportent un risque de ce que l’on appelle le faux positif.
Comme vous pouvez le deviner, un faux positif se produit lorsque le résultat d’un test indique qu’une variation affiche une amélioration, alors que ce n’est pas le cas. En matière de faux positifs, il arrive souvent que la version B donne les mêmes résultats que la version A (et non pas qu’elle soit moins performante que la version A).
Loin d’être inoffensifs, les faux positifs ne sont certainement pas une raison d’abandonner l’A/B testing. Vous pouvez plutôt ajuster votre intervalle de confiance pour l’adapter au risque lié à un potentiel faux positif.
La probabilité de gain par les statistiques bayésiennes
Vous avez probablement déjà entendu parler de la règle de probabilité de gain de 95 %.
Autrement dit, on considère qu’un test est statistiquement significatif lorsque l’on atteint un seuil de certitude de 95 % : vous êtes sûr à 95 % que votre version B performe comme indiqué, mais il existe toujours 5 % de risques que ce ne soit pas le cas.
Pour de nombreuses campagnes marketing, ce seuil de 95 % est probablement suffisant. Mais si vous menez une campagne particulièrement importante dont les enjeux sont considérables, vous pouvez ajuster votre seuil de probabilité de gain pour qu’il soit encore plus précis : 97 %, 98 % ou même 99 %, excluant ainsi pratiquement le moindre risque de faux positif.
Si l’on peut penser qu’il s’agit d’une valeur sûre (et c’est la bonne stratégie pour les campagnes de premier plan), il ne faut pas l’appliquer à tout va.
Voilà pourquoi :
- Pour atteindre ce seuil plus élevé, vous devez attendre les résultats plus longtemps, ce qui vous laisse moins de temps pour récolter les bénéfices d’une issue positive.
- De manière implicite, vous n’obtiendrez un gagnant qu’avec un gain plus important (ce qui est plus rare), et vous abandonnerez les améliorations mineures qui peuvent quand même changer la donne.
- Si vous avez un faible volume de trafic sur votre page web, vous voudrez peut-être envisager une approche différente.
Les tests bayésiens limitent les faux positifs
Il faut également garder en tête que puisque l’approche bayésienne fournit un intervalle de gain et que les faux positifs n’apparaissent virtuellement que légèrement meilleurs qu’en réalité, vous n’avez alors que très peu de chances d’implémenter un faux positif.
Prenons un scénario courant pour illustrer ce propos. Imaginons que vous exécutiez un test A/B pour vérifier si le nouveau design d’une bannière promotionnelle augmente le taux de clics sur le CTA. Votre résultat indique que la version B est plus performante avec une probabilité de gain à 95 % mais le gain est infime (amélioration médiane d’1 %). Même s’il s’agit d’un faux positif, il y a peu de chances que vous déployez la version B de la bannière sur l’ensemble de votre site car les ressources nécessaires à son implémentation n’en vaudraient pas la peine.
Mais, comme l’approche fréquentiste ne fournit pas cet intervalle de gain, vous seriez plus tenté de mettre en place le faux positif. Certes, ce ne serait pas la fin du monde : la version B offre certainement la même performance que la version A. Cependant, vous gaspilleriez du temps et de l’énergie sur une modification qui ne vous apporterait aucune valeur ajoutée.
Ce qu’il faut retenir ? Si vous jouez la carte de la sécurité et que vous attendez un seuil de confiance trop élevé, vous passerez à côté de plusieurs petits gains, ce qui serait également une erreur.
En conclusion
Alors, quelle approche est la meilleure : fréquentiste ou bayésienne ?
Comme nous l’avons déjà évoqué, les deux approches sont des méthodes statistiques parfaitement valables.
Mais chez AB Tasty, nous avons choisi l’approche bayésienne car nous estimons qu’elle aide nos clients à prendre de meilleures décisions commerciales. Elle permet également une plus grande flexibilité et une maximisation des bénéfices (allocation dynamique de trafic). En ce qui concerne les faux positifs, ils peuvent survenir que vous optiez pour l’approche fréquentiste ou bayésienne… mais il y a de moins de risque que vous vous y laissiez prendre avec cette dernière. Au bout du compte, si vous cherchez une plateforme d’A/B testing, l’important est d’en trouver une qui vous fournira des résultats fiables et facilement interprétables.
